새소식
반응형
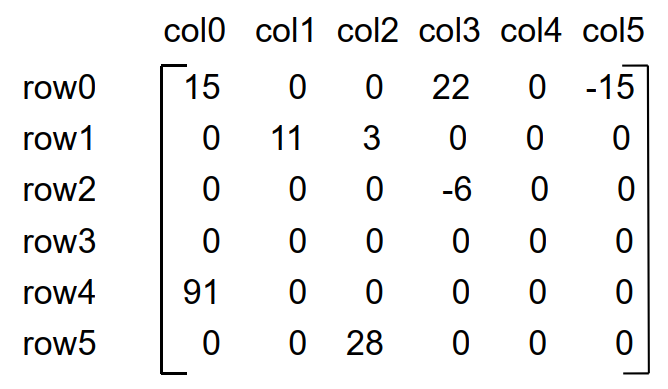
희소행렬은 행렬의 값이 대부분 0인 행렬을 의미한다. 원 핫 인코딩 또는 마켓의 장바구니 데이터가 대표적으로 희소행렬로 표현된다. 다음 그림은 희소행렬의 예시인데, 이 경우 자료를 그대로 저장하는 것은 너무나도 비효율적이다. 이 글에서는 희소행렬의 효율적인 저장법에 대해 알아본다.
가장 쉬운 형태의 구현이다. 필자가 희소행렬을 맨 처음 배웠을 때 생각한 구현 방법이다. N x N 크기의 행렬이 N개의 리스트 포인터를 가진 벡터로 표현된다. 다만 액세스 속도가 똥임으로 사용할 이유가 없다.
행렬의 모든 값을 (row, col, val)의 형태를 가진 리스트로 표현한다. 원래 형태에 비해서 접근하는 속도가 느리긴 하지만 ((row, col)의 인덱스를 찾아야하기 때문), 가장 쉽게 쓰이는 방식이다. 벡터의 첫 값은 보통 메타데이터를 넣어준다 (row의 수, col의 수, val의 수).
COO에서 row의 값을 그대로 저장하지 않고 시작 인덱스만 저장한다. COO에 비해 더욱 적은 메모리를 사용하므로 더 빠른 연산을 지원한다. 일반적인 라이브러리에서 쓰는 방식.
다음 코드는 scipy에서 제공하는 희소행렬 기능을 사용한 것이다.
import scipy.sparse as ss
import numpy as np
sparse = np.array([[1, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1],
[0, 1, 0, 1, 0, 0],
[1, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 1]])
COO = ss.coo_matrix(sparse)
CSR = ss.csr_matrix(sparse)
print(COO)
print()
print(CSR.indptr)
print()
print(COO.todense())
print()
print(CSR.todense())
rCOO = CSR.tocoo()
rCSR = COO.tocsr()다음 이미지는 위 코드에 대한 결과이다. sparse 행렬에 대해 COO와 CSR 방식으로 희소행렬을 구성하고 COO의 값 구성, CSR의 행 시작 인덱스를 출력했다. 또한 이렇게 얻은 희소행렬을 원래 행렬로 되돌려 보기도 했다. 추가로, Scipy에서는 COO와 CSR의 전환도 자유로우니 쓰길 바란다.

COO에서 쉽게 생기는 오해 중 하나가, Transpose가 무조건 쉬울 것이라고 생각하는 것이다. 실제로 원래 형태에서는 Transpose를 취하기 때문에 $O(row * col) = O(row^2)$ 만큼의 시간이 드는 것에 반해, COO에서는 벡터를 순회하면서 row와 col의 값만 바꿔주면 된다고 생각할 수 있으니, 시간복잡도를 $O(N)$라고 판단하는 것이다 (더더욱, 해당 행렬이 희소행렬이므로 $N << row*col$이기 때문에 이런 오해가 가중될 수 있다). 다만, 일반적으로 COO에서는 데이터를 row와 col에 대한 오름차순으로 저장하기 때문에 새롭게 정렬해줘야 한다. 즉, 일반적으로 가장 빠른 $O(nlog\; n)$ 정렬 알고리즘을 사용한다고 했을 때 시간복잡도는 $O(n^2 log\; n)$ 이 된다. 즉, 이론적으로 n이 row만큼만 되어도 원래 자료구조에서 Transpose하는 것이 더 빠르다. 그리고 이렇게 n이 row개 만큼 저장되는 희소행렬 구조가 있는데, 바로 원 핫 인코딩 scheme 데이터이다. 모든 행에 1이 딱 한 번만 포함되어 있으므로 n이 row번 등장한다.
하지만 역시, 과학자들은 이런거 눈 뜨고 못 있는다. Fast Transpose라는 COO에서 작동하는 고속 transpose 알고리즘을 만들었다. row의 값 (원래 행렬의 col 값)마다 존재하는 value들이 몇 개가 있는지 체크하고 이를 통해, 이 원래 행렬의 값들이 전치행렬의 어디에 들어가야 할지 포인터를 잡아준다.
아래 코드는 C에서 작동하는 Fast Transpose이다. 코드를 가지고 다닐 필요는 없다. 어차피 numpy 라이브러리에서 transpose 메서드 한방이면 전치되니까. 어떤 방식으로 돌아가는지 이해만 하면된다.
typedef struct {
int row;
int column;
int value;
}matrix;
void fastTranspose(matrix* a, matrix* b) {
b[0].row = a[0].column;
b[0].column = a[0].row;
b[0].value = a[0].value;
int rowTerms[10];
int startingPosition[10];
for(int i = 0; i < a[0].column; i++) {
rowTerms[i] = 0;
}
for(int i = 1; i <= a[0].value; i++) {
rowTerms[a[i].column]++;
}
startingPosition[0] = 1;
for(int i = 1; i <= a[0].column; i++) {
startingPosition[i] = startingPosition[i-1] + rowTerms[i-1];
}
for(int i = 1; i <= a[0].value; i++) {
int j = startingPosition[a[i].column]++;
b[j].row = a[i].column;
b[j].column = a[i].row;
b[j].value = a[i].value;
}
}여기서 개선점은 굳이 startingPosition을 이용하지 않고 변수 2개만으로 같은 기능을 구현할 수 있다.
typedef struct {
int row;
int column;
int value;
}matrix;
void fastTranspose(matrix* a, matrix* b) {
b[0].row = a[0].column;
b[0].column = a[0].row;
b[0].value = a[0].value;
int rowTerms[10];
for(int i = 0; i < a[0].column; i++) {
rowTerms[i] = 0;
}
for(int i = 1; i <= a[0].value; i++) {
rowTerms[a[i].column]++;
}
temp1 = 1;
temp2;
for(int i = 1; i <= a[0].column; i++) {
temp2 = rowTerms[i];
rowTerms[i] = temp1;
temp1 += temp2;
}
for(int i = 1; i <= a[0].value; i++) {
int j = rowTerms[a[i].column]++;
b[j].row = a[i].column;
b[j].column = a[i].row;
b[j].value = a[i].value;
}
}즉 역할이 끝난 rowTerms를 StartingPosition의 역할을 하도록 바꾸는 것이다.
| 자료구조 개요 (0) | 2020.05.17 |
|---|
소중한 공감 감사합니다